This quick tutorial will show you how to create a unique identifier for each case – i.e., each person, experimental subject, etc – within a data set in SPSS.
The advantage of doing this is it disambiguates cases that might otherwise be confused – for example, if you had two John Smiths in your sample.
Quick Steps
- Click on Transform -> Compute Variable
- Give your new variable the name “ID” in the Target Variable box
- Click on All in the Function Group list, and then drag and drop $Casenum into the Numeric Expression box at the top
- Press OK
- You’ll be able to see your new ID variable in SPSS’s Data View
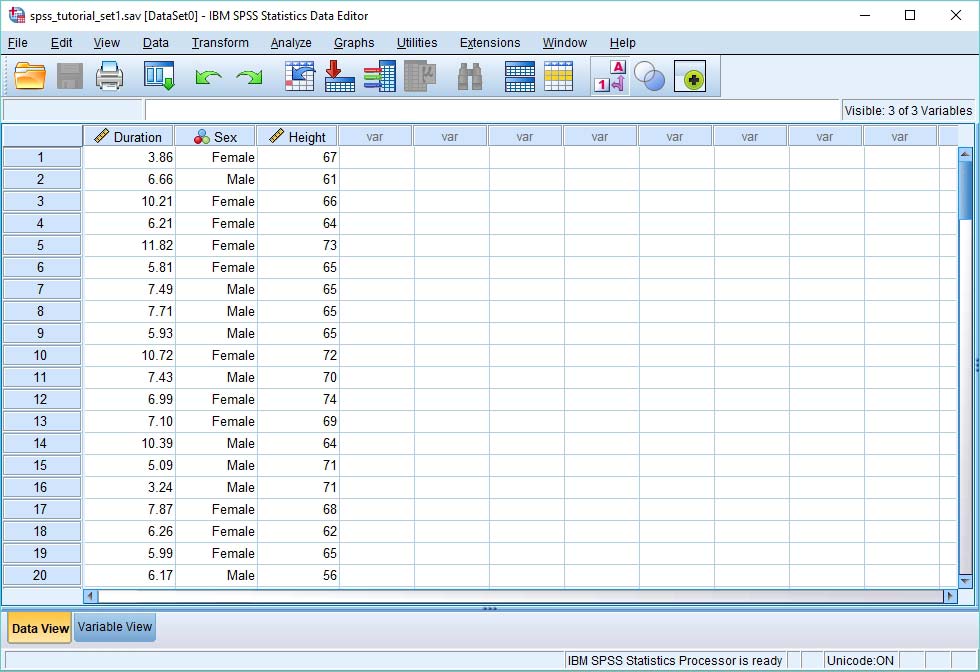
The Data
As you can see below, we have three variables in our data set, but nothing to distinguish individual cases from each other. The addition of a variable containing integers functioning as unique identifiers will sort out this issue.
Add an ID
We’re going to add a variable that will contain a set of number IDs by using the Transform -> Compute Variable menu item.
The Compute Variable dialog box looks like this.
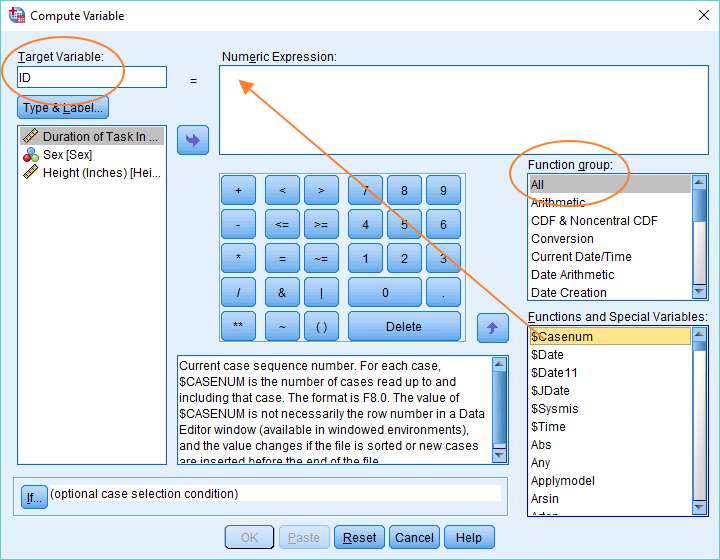
There are three things you’ve got to do to set up this box to generate a set of unique identifiers.
The first is to specify the name of your target variable in the Target Variable box. You should name this ID (as above).
The second thing is to select All in the Function group on the right of the dialog. This will allow you to select $Casenum in the Functions and Special Variables box. The $Casenum variable is just the number of cases read up to and including the current case. So, for example, the function will return the number 3 for the third case (normally, but not always, the third row in the Data View), the number 4 for the fourth case, and so on. This will generate a set of unique integers that can function as ID numbers.
The third thing is to drag the $Casenum function into the Numeric Expression box (as per the red arrow above).
That’s it. If you press OK, SPSS will generate a variable named ID that will contain a unique identifier for each case in the Data View.
The Result
Here you can see the final result.
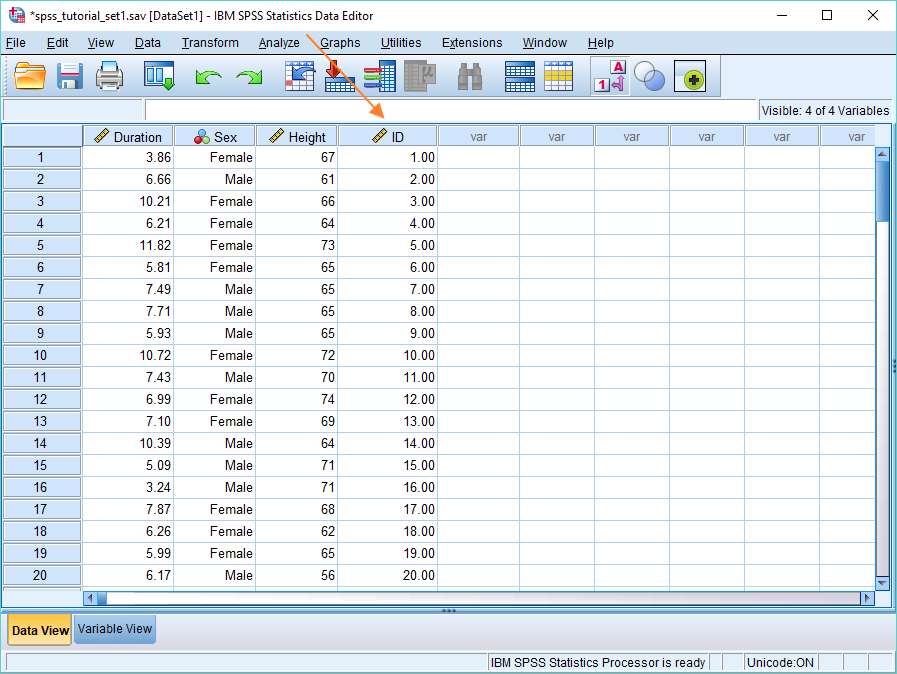
The new ID variable contains a unique identifier for each case in the data set.
There are a few things you could do to tidy this up – for example, get rid of the decimal point and drag the ID variable over to the left so it appears in the first column – but really this is job done. Each case is now associated with a unique identifier.
***************
Right, that’s it for this quick tutorial. You should now be able to create a unique ID number for each of your cases in a SPSS data set.